Causal evaluation for LLM systems
The problem: You have abundant cheap metrics (LLM-as-judge, clicks, thumbs) that don't map to what you care about and are easy to game. You have expensive labels (expert audits, A/B outcomes, retention) that are robust but scarce.
The solution: Causal Judge Evaluation (CJE) calibrates cheap scores against just 5% oracle labels, then evaluates at scale with valid uncertainty. Aim at the right target without breaking the budget.
Quick overview
30-minute read
Prefer video?
Watch CJE Explained
Quick Overview
4 min — The problem and the solution
Full Introduction
8 min — The causal DAG, pipeline, and transport tests
Why Raw Judge Scores Fail
Standard LLM-as-judge evaluation breaks in three predictable ways. CJE detects and corrects each one.
1. Preference Inversion
Higher judge scores can predict lower real-world quality. "You're absolutely right!" scored 10/10 on politeness while tanking user trust.
2. Invalid Confidence Intervals
Standard error bars assume the judge is perfect. In our Arena benchmark, naive 95% CIs captured the truth 0% of the time.
3. Off-Policy Evaluation Failure
Importance sampling fails even with high effective sample size. Coverage gaps make historical log analysis unreliable.
New here?
Start with the Learning Path
A guided progression from core concepts to implementation. Go as deep as you need (most practitioners stop at step 4).
What CJE Returns
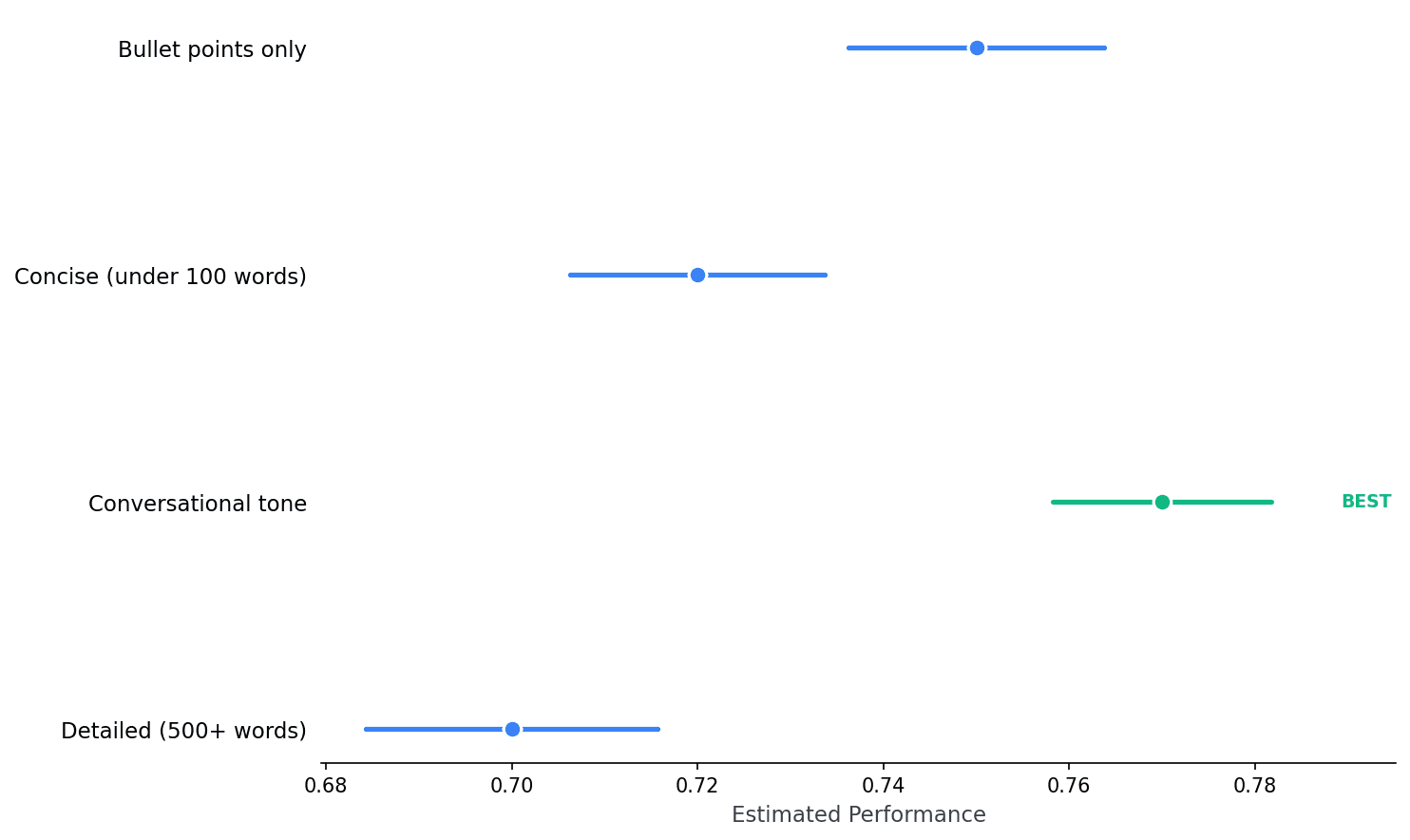
Compare prompt variants. Calibrated estimates with honest error bars. The best policy is marked automatically.
What CJE Does
Calibrates cheap metrics to expensive outcomes
Learn how judge scores map to real outcomes (conversion, retention, expert audits). Use that mapping at scale.
Reports honest confidence intervals
Accounts for both evaluation uncertainty and calibration uncertainty. No false wins on noisy data.
Detects when calibration breaks
Built-in drift monitoring and transportability tests. Know when your judge→outcome mapping stops working.
pip install cje-evalIntegrations
CJE works with your existing evaluation stack.
Validated on 5,000 Real Chatbot Arena Evaluations
Benchmarked 14 estimators on real LMSYS Arena prompts with GPT-4.1 Nano as cheap judge and GPT-5 as oracle. 99% pairwise ranking accuracy at 14× lower cost. Uncalibrated judges produce 0% CI coverage. CJE restores valid 95% coverage.
Note: Oracle = GPT-5 simulating expert judgment, not human validation. See methodology details in full results.